C++11부터는 람다식(Lambda Expression)이 지원된다. 람다가 무엇인지 알아보기 전에 함수 객체(Functor or Function object)에 대해서 알아야 한다. 함수 객체란 객체를 함수 호출 연산자 '()'를 오버로딩해서 함수처럼 호출될 수 있게한 객체를 의미한다. 예를 들면 아래와 같다.
class functor
{
public:
functor() {}
~functor() {}
void operator()()
{
std::cout << "This is functor" << std::endl;
}
};
int main()
{
functor func;
func(); // This is functor 출력
return 0;
}그렇다면 이 함수 객체를 사용하면 어떤 점이 좋은걸까?
1. 함수 객체는 기본적으로 클래스 객체이므로 멤버 변수, 멤버 함수를 활용할 수 있다.
2. 함수 포인터로 호출되는 경우 인라인될 수 없지만 함수 객체를 사용하면 인라인될 수 있어 성능 향상에 도움이 될 수 있다(기본적으로 클래스의 선언 부분에 함수를 선언하고 동작까지 정의하면 인라인된다).
3. STL에선 함수 객체를 많이 사용하고 있기 때문에 코드를 읽기 위해서라도 함수 객체를 반드시 알아야 한다.
람다 표현식을 배우기 전에 함수 객체에 관한 용어를 몇가지 알아야 한다.
위의 함수 객체처럼 인자없이 그냥 func()이렇게 호출되는 함수 객체를 발생자(Generator), 하나의 인자를 필요로 하면 단항 함수(Unary function), 두개를 필요로 하면 (Binary function)이라고 부른다. 그리고 호출 연산자 '()'의 리턴타입을 bool로 되어 있는 함수 객체를 술어(Predicate)라고 하는데 마찬가지로 인자가 하나만 필요한 함수 객체를 단항 술어(Unary predicate), 2개 필요한 함수 객체를 이항 술어(Binary predicate)라고 한다.
술어를 인자 타입으로 요구하는 함수들을 이용해서 함수객체 또는 람다 표현식을 사용할 수 있다. 예를 들어 remove_if 함수의 시그니쳐를 보자
template< class ForwardIt, class UnaryPredicate >
ForwardIt remove_if( ForwardIt first, ForwardIt last, UnaryPredicate p );ForwardIt는 이전에 배운 forward iterator(++, 비교 연산 및 *, ->를 이용한 역참조만 가능한 iterator) 타입을 의미하며 UnaryPredicate가 위에서 언급한 단항 술어를 의미한다. 참고로 remove_if함수는 실제로 element를 삭제하는게 아니라 술어 p라는 (삭제) 조건을 만족하지 않는 element들을 순서대로 container의 앞으로 '복사'해준다. 이게 무슨 의미인가 하면
#include <iostream>
#include <vector>
#include <algorithm>
class functor
{
public:
functor() {}
~functor() {}
bool operator()(int x) {
return ((x % 2) == 0);
}
};
int main()
{
std::vector<int> vec = { 1,2,3,4,5,6,7,8,9,10 };
functor foo;
std::remove_if(vec.begin(), vec.end(), foo);
for (int i = 0; i < vec.size(); ++i)
{
std::cout << "vec[" << i << "]: " << vec[i] << " "; // 1 3 5 7 8 6 7 8 9 10
}
std::cout << "end: " << *(--(vec.end())) << std::endl; // 10
}출력값이 저렇게 나오는 이유를 그림으로 표현해봤다.

cppreference에는 다음과 같이 설명하고 있다.
Removes all elements satisfying specific criteria from the range [first, last) and returns a past-the-end iterator for the new end of the range.
Removing is done by shifting (by means of copy assignment (until C++11)move assignment (since C++11)) the elements in the range in such a way that the elements that are not to be removed appear in the beginning of the range.
remove_if는 실제로 삭제가 일어나서 container에 조건을 만족하는 element들이 사라진다기 보다는 조건을 만족하는 원소들이 자릴 비워주고 그 빈 자리를 오른쪽에서 밀어내서(?) 채워주고, 남은 자리는 원래 그 자리의 원소들로 채우는 방식인 것 같다.
사실 완전히 조건을 만족하는 원소들을 지우기 위해선 아래처럼 erase함수를 함께 써줘야한다.
int main()
{
std::vector<int> vec = { 1,2,3,4,5,6,7,8,9,10 };
functor foo;
vec.erase(std::remove_if(vec.begin(), vec.end(), foo), vec.end());
for (int i = 0; i < vec.size(); ++i)
{
std::cout << "vec[" << i << "]: " << vec[i] << " "; // 1 3 5 7 9
}
}위에서 볼 수 있듯이 remove_if의 인자로 함수 객체를 사용한 것을 확인할 수 있다. 그런데 만약에 functor 클래스가 main과 다른 파일에 저장되어 있다면 코드를 처음 보는 사람 입장에서는 클래스안에 '()'연산자가 오버로딩된 부분과 함수 객체가 쓰인부분을 왔다갔다하면서 코드를 읽어야 할 것이다. 사실 저렇게 간단한 함수인데 그러기에는 너무 불편하다. 그래서 '()' 연산자 오버로딩된 동작이 간단하다면 함수 객체가 쓰이는 곳에 바로 정의해버리면 편할 것이다. 그래서 나온것이 람다 표현식이다.
람다 표현식(Lambda expression)
위에서 함수 객체를 이용해서 짝수를 지우는 식을 람다 표현식으로 바꿔보면 아래와 같다.
int main()
{
std::vector<int> vec = { 1,2,3,4,5,6,7,8,9,10 };
functor foo;
vec.erase(std::remove_if(vec.begin(), vec.end(), [](int i) ->int {
return ((i % 2) == 0);
}), vec.end());
for (int i = 0; i < vec.size(); ++i)
{
std::cout << "vec[" << i << "]: " << vec[i] << " "; // 1 3 5 7 9
}
}람다 표현식을 만드는 방식은 간단하다.

참고로 C++ 20부터는 템플릿 인자까지도 지원된다.
[] : capture는 람다식 내에서 선언하지 않았고, 같은 블록내에서 가져올 인자를 의미한다. static 변수는 capture 불가.
( ) : 일반 함수처럼 인자 목록이 있다면 적어주면 된다.
trailing-return type : '-> 리턴 타입' 이렇게 적어주면 된다. optional이라 적어줘도 되고 안적어줘도 컴파일러가 알아서 유추하지만 가독성을 위해서 적어주는게 좋다.
{ } : 함수 body
int main()
{
std::vector<int> vec = { 1,2,3,4,5,6,7,8,9,10 };
functor foo;
int add = 10;
std::for_each(vec.begin(), vec.end(), [add](int& i) -> void {
i = i + add;
});
}위의 코드에선 같은 블록에 있는 add라는 인자를 capture를 이용해서 가져왔다. 위의 경우에는 capture by value방식으로 가져와서 복사된 add의 값을 이용한것인데, 만약 캡쳐로 가져온 변수자체를 가져와서 값을 변경시키고 싶다면 capture by reference 방식으로 아래와 같이 쓸 수 있다.
int main()
{
int add = 0;
std::for_each(vec.begin(), vec.end(), [&add](int i) -> void {
add += i;
});
std::cout << "add : " << add << std::endl;
}캡쳐 부분을 총정리하면 아래와 같다.
[] : 아무것도 캡처하지 않음
[&x]: x만 Capture by reference
[x] : x만 Capture by value
[&] : 모든 외부 변수를 Capture by reference
[=] : 모든 외부 변수를 Capture by value
[x,y] : x,y 를 Capture by value
[&x,y] : x는 Capture by reference , y는 Capture by value
[&x, &y] : x,y 를 Capture by reference
[&, y] : y 를 제외한 모든 값을 Capture by reference
[=, &x] : x 를 제외한 모든 값을 Capture by value
출처: https://vallista.tistory.com/entry/C-11-Lambda-Expression-람다-표현식-함수-객체-Functor [VallistA]참고로 그냥 [=]를 쓰면 편하지 않느냐라고 생각할 수 있는데 아래처럼 복사생성자가 쓸데없이 많이 호출돼서 비효율적일 수 있기 때문에 정말 필요한 경우에만 좋다.
class functor
{
public:
int Num;
functor() { std::cout << "constructor" << std::endl; }
~functor() {}
functor(const functor& f) { std::cout << "copy constructor" << std::endl; }
};
int main()
{
functor f; // 생성자 호출
f.Num = 100;
auto lambda = [=](int i) -> void {i = f.Num; }; // 객체 f가 capture by value되면서 복사 생성자 호출
auto lambda2 = lambda; // 복사 생성자 호출
}
람다 표현식을 자주 사용하려면 다양한 예시와 함께 predicate를 인자로 받는 다양한 함수(ex. remove_if, for_each, find_if)들도 함께 아는것이 좋을듯 하다. 끝으로 람다 표현식의 다양한 예시를 살펴보자(코드 출처: https://m.blog.naver.com/eso777/221727943597)
int main()
{
// 람다 표현식을 함수 포인터를 변수에 할당하듯이 변수에 할당 할 수 있다.
auto f = [](int Num) { return (Num % 2) == 0; };
// 함수 객체와 마찬가지로 호출 연산자 '()'를 이용해서 호출 가능
std::cout << f(3) << std::endl;
auto fuctor1 = [](int Num) { return (Num % 2) == 0; };
// error(람다 표현식은 임시 객체. 즉 rvalue이므로 에러)
auto& functor2 = [](int Num) { return (Num % 2) == 0; };
auto&& fuctor3 = [](int Num) { return (Num % 2) == 0; };
return 0;
}int main()
{
auto f1 = [](int Num) { return (Num % 2) == 0; };
auto f2 = [](int Num) { return (Num % 2) == 0; };
// 서로 타입이 다름
std::cout << typeid(f1).name() << std::endl;
std::cout << typeid(f2).name() << std::endl;
return 0;
}인자, 리턴 타입이 같은 람다 표현식이라도 타입이 다르게 출력된다.

람다 표현식을 담을 수 있는 변수는
1. auto
2. 함수 포인터
3. std::function< 리턴타입(인자) >
이렇게 세가지가 있다.
int main()
{
auto f1 = [](int Num) { return (Num % 2) == 0; };
bool (*f2)(int) = [](int Num) { return (Num % 2) == 0; };
std::function<bool(int)> f3 = [](int Num) { return (Num % 2) == 0; };
f1(3); // 인라인됨
f2(3); // 함수 포인터로 점프하고 나서 어떤 코드인지 알기 때문에 인라인 안됨
f3(3); // 인라인됨
return 0;
}아래는 람다 표현식을 인자로 받는 방법에 대한 예시이다.
void boo(int (*f)(int))
{
f(3);
}
void bar(std::function<void()> f)
{
f();
}
int main()
{
auto f1 = [](int Num) { return Num * 2; };
auto f2 = [] () -> void { std::cout << "Hello" << std::endl; };
boo(f1);
bar(f2);
return 0;
}당연히 함수 포인터 변수, std::function을 이용한 객체에 람다 표현식을 할당할 수 있으므로, 위의 경우처럼 함수 포인터, std::function를 이용해서도 람다 표현식을 인자로 받을 수 있다(C++20부터는 auto를 함수 인자로도 쓸 수 있다고 하니 auto를 이용해서 람다를 인자로 받을 수도 있을 것이다). 하지만 template을 이용할 때를 살펴보면
template <typename T>
void foo1(T f)
{
}
template <typename T>
void foo2(T& f)
{
}
template <typename T>
void foo3(T&& f)
{
}
template <typename T>
void foo4(const T& f)
{
}
int main()
{
auto f = [](int Num) { return Num * 2; };
return 0;
}
과연 이 상황에서 foo1, foo2, foo3중 무엇이 올바르게 람다 표현식을 받는 것일까. 우선 foo2는 에러가 난다. 왜냐하면 위에서 언급했듯이 람다 표현식은 임시 객체로써 rvalue이기 때문이다. 그럼 foo1, foo3, foo4 셋중에 무엇이 올바른 걸까? 셋 다 컴파일은 될 것이다. 다만 foo1, foo4는 제약이 있다.
먼저 foo1은 람다 표현식에서 캡쳐된 변수들이 함수 호출시 복사될 것이다. 예를 들어서 아래와 같은 상황이라고 가정해보자
class Node
{
public:
Node() {}
~Node() {}
Node(const Node& n) { std::cout << "copy constructor" << std::endl; }
};
template <typename T>
void foo1(T f)
{
}
int main()
{
Node node1;
auto f = [node1](int Num) { return Num * 2; };
std::cout << "************" << std::endl;
foo1(f);
return 0;
}결과는 아래 사진에서 볼 수 있듯이, 람다 표현식에 node1이 캡쳐될 때 한번, foo1이 호출될 때 한번 복사 생성사가 불필요하게 호출된다.
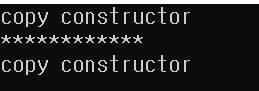
더 큰 문제는 만약에 아래와 같은 상황이면 foo1은 사용이 불가능하다.
int main()
{
auto lambda = [foo = std::make_unique<int>()](){};
foo1(lambda);
return 0;
}
unique_ptr은 복사될 수 없기 때문에 당연히 이 상황에서 foo1의 방식대로는 람다 표현식을 인자로 받을 수 없다.
foo4도 제약이 있다. f가 const이기 때문에 람다 표현식에서 mutable을 사용할 수 없다. 여기서 mutable은 람다 표현식에서 capture by value를 람다 표현식 body에서 바꿀 수 있게 해주는 것이다. 아무것도 안적으면 디폴트로 constexpr인데, constexpr은 람다 표현식 body에서 캡쳐를 바꿀 수 없다. 즉, [ ] 에서 capture by value된 값들은 원래 람다 표현식 body에서 값을 변경할 수 없다.
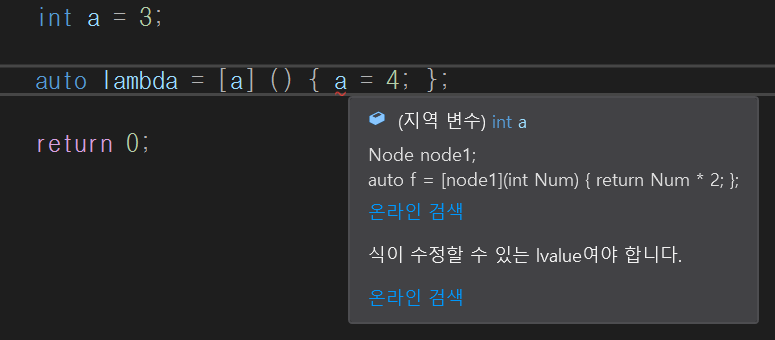
하지만 여기에 mutable을 붙여주면 가능하다. 물론 body내에서 복사된 값을 바꾸는 것이므로 람다 표현식 내에서만 값이 바뀌는 것이고, 원래 a값은 그대로다.

다시 foo4의 인자를 받는 방식으로 돌아와서 foo4는 T타입의 f가 const라는 것이므로, f라는 객체가 호출되면 호출 연산자 '()'가 상수 함수라는 것이다. 즉, f가 호출됐을 때 함수 내부에서 아무런 값도 바꾸면 안된다는 의미다. 쉽게 이야기하면, foo4의 방식처럼 람다 표현식을 인자로 받으면 mutable 람다 표현식을 못쓴다는 의미다.
foo3의 방식은 그냥 &&가 붙으면 rvalue reference로 rvalue만 받을거라 생각하지만 template으로 타입 T라는(무슨 타입인지 모르는) f에 &&가 붙으면 universal reference가 된다(universal reference에 대해 아직 잘 몰라서 추후 공부하고 추가로 글을 써볼 예정이다).
결론부터 이야기하면 universal reference인 foo3은 현재 lvalue/rvalue reference모두 인자로 받을 수 있는 상황이다. 따라서 foo3이 가장 바람직한? 람다식을 인자로 받는 방식이다.
이번에 람다 표현식을 공부하면 할수록 모르는게 너무 많이 나왔다(ex. std::forward, universal reference 등등). 하나를 몰라서 검색하면 모르는거 3~4개가 나오니 도무지 앞으로 진도가 안나기도 하고 한번 읽는다고 이해가 되는 개념이 아니라 조금 힘들었다. 하지만 내가 모르는게 많다는 것을 체감하고 뭘 공부해야 하는지 계획을 세워나가고 가시적인 목표가 생긴다는건 즐거운 일인것 같다.
Reference
https://en.cppreference.com/w/cpp/algorithm/remove
std::remove, std::remove_if - cppreference.com
(1) template< class ForwardIt, class T > ForwardIt remove( ForwardIt first, ForwardIt last, const T& value ); (until C++20) template< class ForwardIt, class T > constexpr ForwardIt remove( ForwardIt first, ForwardIt last, const T& value ); (since C++20) te
en.cppreference.com
https://openmynotepad.tistory.com/23
C++11) 람다식 (Lambda Expression) 과 std::function
<개요> c++ 11부터 함수 객체를 조금 더 짧게 작성하자는 취지로 람다식이 등장했습니다. 람다식과 std::function에 대해 작성합니다. 만약 함수 객체 ( 단항 술어, 이항 술어 등 ) 을 모르신다면 STL 부
openmynotepad.tistory.com
https://www.codeguru.com/cpp/cpp/cpp_mfc/stl/Lambdas-in-VC-2010-16693.htm
Lambdas in VC++ 2010
Visual Studio 2010 comes with several changes to the C++ compiler to support new features that will be available in the new version of the standard, currently known as C++0x. The new compiler includes, in addition to what was already released in the namesp
www.codeguru.com
https://m.blog.naver.com/eso777/221727943597
Modern C++ 교육 4일차
Templates A template is a C++ entity that defines one of the following: a family of classes (clas...
blog.naver.com
'공부 > C || C++' 카테고리의 다른 글
| C++ iterator를 reverse_iterator로 변환시 같은 element를 가리키지 않는 이유 (0) | 2021.07.30 |
|---|---|
| C++ 11 universal reference, std::forward (0) | 2021.07.25 |
| C++ 템플릿 특수화 (0) | 2021.07.24 |
| C++ 템플릿 클래스/함수 헤더파일에 선언과 정의 모두 해줘야 하는 이유 (0) | 2021.07.23 |
| C++ static variable, static member variable, static member function (0) | 2021.07.23 |