C++ 11에는 내가 몰랐던, 혹은 사용하는지도 몰랐던 여러가지 syntax들과 기능들이 있었다. 이번 기회에 정리해보면 좋을 것 같다. 이번 글에서는 Rvalue reference에 대해서 알아보자
먼저 Rvalue가 뭔지부터 알아보자. 이름만 보면 우측값인데 그런 의미 보다는 C++에서는 임시로 생성됐다가 바로 없어지는 값을 의미한다.
Rvalue가 있으면 Lvalue도 있을텐데 Lvalue는 반대로 표현식 이후 scope내에서 다시 사용 가능한 값을 의미한다.
코드로 예를 들어보면
int a = 3 + 4; // 3+4는 rvalue
int b = 10; // 10은 rvalue
int sum = a+b; // a+b는 rvalue
int *p = &a; // &a는 표현식이 종료되면 더 이상 참조할 수 없기 때문에 rvalue!
cout << string("one"); // string("one")도 &a와 같은 이유로 rvalue
++x; // ++x는 lvalue
x++; // x++는 rvalue
신기한건 ++x는 Lvalue인데 x++는 Rvalue라고 한다. 왜 그런지 찾아보니 ++x는 1만큼 증가시킨 자기 자신을 리턴하기 때문이고, x++는 자기 자신의 복사본을 리턴하고 증가시키기 때문이라고 한다.
Rvalue는 위에서 언급했듯이 표현식 이후에 바로 없어진다고 했다. 그 말은 표현식 이후로 참조가 다시는 불가능하다는 의미다. 이런 다시 참조가 불가능한 임시 객체를 위해서 불필요하게 복사(= copy)를 하지 않고 상대적으로 비용이 더 싼 이동(= move semantic)을 통해 소유권을 이전하게 해주는 것이 Rvalue reference다. 즉 Rvalue reference를 이용하면 move semantic을 사용할 수 있다. 그렇다면 move semantic이 어떤 것이고, 어떤 좋은점이 있는지 그리고 어떤 상황에서 쓰면 좋은지 알아보자. (코드 출처: https://docs.microsoft.com/ko-kr/cpp/cpp/move-constructors-and-move-assignment-operators-cpp?view=msvc-160 )
#include <iostream>
#include <algorithm>
#include <vector>
class MemoryBlock
{
public:
// Simple constructor that initializes the resource.
explicit MemoryBlock(size_t length) : _length(length), _data(new int[length])
{
std::cout << "Constructor Length : " << _length << std::endl;
}
// Destructor.
~MemoryBlock()
{
std::cout << "Destructor Length : " << _length << std::endl;
if (_data != NULL)
{
std::cout << "Deleting resource." << std::endl;
// Delete the resource.
delete[] _data;
}
}
// Copy constructor.
MemoryBlock(const MemoryBlock& other) : _length(other._length), _data(new int[other._length])
{
std::cout << "Copy Constructor Length : " << _length << std::endl;
//std::copy(other._data, other._data + _length, _data);
memcpy_s(_data, _length, other._data, _length);
}
// Copy assignment operator.
MemoryBlock& operator=(const MemoryBlock& other)
{
std::cout << "Copy assignment operator Length : " << other._length << std::endl;
if (this != &other)
{
// Free the existing resource.
delete[] _data;
_length = other._length;
_data = new int[_length];
//std::copy(other._data, other._data + _length, _data);
memcpy_s(_data, _length, other._data, _length);
}
return *this;
}
// Retrieves the length of the data resource.
size_t Length() const
{
return _length;
}
private:
size_t _length; // The length of the resource.
int* _data; // The resource.
};
int main()
{
std::vector<MemoryBlock> vTemp;
vTemp.push_back(MemoryBlock(50));
std::cout << "====================" << std::endl;
vTemp.push_back(MemoryBlock(100));
std::cout << "====================" << std::endl;
vTemp[0] = MemoryBlock(75);
std::cout << "====================" << std::endl;
return 0;
}
위 코드를 실행해보면 다음과 같은 결과를 얻을 수 있다.
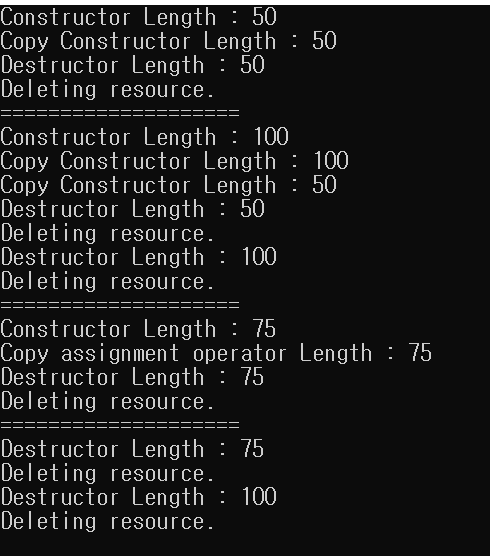
결과를 보면 우선 v.push_back인자로 넣어준 MemoryBlock(50) 임시객체가 만들어지면서 생성자가 호출된다. vector의 push_back의 경우, vector밖과 내부 모두에서 임시 객체를 만들고 밖에서 만든 임시 객체를 안에서 만든 임시 객체로 복사시켜준다. 그래서 copy constructor가 한번 불렸고, 밖에서 만들어진 임시 객체는 소멸자를 호출하면서 사라진다.
벡터는 원래 할당된 공간보다 더 많은 element가 들어오면 원래 벡터의 2배만큼의 capacity를 가진 벡터를 새로 만들고, 기존의 벡터에 존재하던 element들을 새로 만들어진 벡터로 복사한다. 그래서 MemoryBlock(100)이 push_back될때는 임시 객체를 위한 생성자 호출과 동시에 새로운 벡터로 복사되므로 생성자와 복사 생성자가 호출되고, 기존의 벡터에 존재하던 MemoryBlock(50)은 새로운 벡터로 복사되기 때문에 복사 생성자가 호출된다. 그 이후 기존의 벡터에 존재하던 MemoryBlock(50)과 임시 객체인 MemoryBlock(100)을 없애기 위해 소멸자가 호출된다.
먼저 벡터 밖에서 생성되는 임시객체 MemoryBlock(75)를 위해서 생성자가 호출된다. 그 이후 vTemp[0] = MemoryBlock(75); 코드는 생성과 동시에 초기화되는게 아니기 때문에 대입 연산자(assignment operator)가 호출된다. 여기서도 마찬가지로 벡터 밖에서 생성된 임시 객체가 벡터 내부에서 생성된 객체로 복사 해주고 이후에 벡터 밖의 임시 객체는 소멸자를 호출해서 소멸된다.
평범한 코드이고, 평소에 자주 사용하던 코드라서 별 문제가 없어 보인다. 하지만 다음 move생성자(move constructor)와 move 대입 연산자(move assignment operator)를 사용하고 결과를 비교해보면 이 코드가 얼마나 비효율적이었는지 알 수 있다.
아래와 같이 move 생성자와 move 대입 연산자를 정의해보자
// Move constructor.
MemoryBlock(MemoryBlock&& other) noexcept
: _data(nullptr)
, _length(0)
{
std::cout << "In MemoryBlock(MemoryBlock&&). length = "
<< other._length << ". Moving resource." << std::endl;
// Copy the data pointer and its length from the
// source object.
_data = other._data;
_length = other._length;
// Release the data pointer from the source object so that
// the destructor does not free the memory multiple times.
other._data = nullptr;
other._length = 0;
}
// Move assignment operator.
MemoryBlock& operator=(MemoryBlock&& other) noexcept
{
std::cout << "In operator=(MemoryBlock&&). length = "
<< other._length << "." << std::endl;
if (this != &other)
{
// Free the existing resource.
delete[] _data;
// Copy the data pointer and its length from the
// source object.
_data = other._data;
_length = other._length;
// Release the data pointer from the source object so that
// the destructor does not free the memory multiple times.
other._data = nullptr;
other._length = 0;
}
return *this;
}move 생성자와 move 대입 연산자에서 포인터나 값을 넘겨주고, 본인은 nullptr를 갖게됨으로써 소유권을 이전해주게 되는 것이다.
move 생성자와 move 대입 연산자를 정의하고 빌드한 결과는 아래와 같이 출력된다
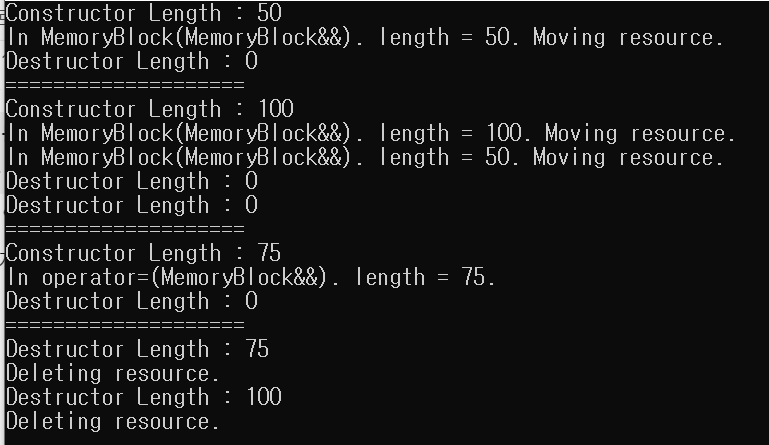
첫번째로 눈에 띄는 점은 복사생성자가 아니라 Move 생성자가 호출되었다는 점이다. 기본적으로 복사 생성자보다 move 생성자가 더 빠르다. 그리고 소멸자가 호출되어도 delete가 호출되지 않은 점을 확인할 수 있다. 생성자에서 만든 객체의 _data 포인터 자체와 _length를 전달해주고 자기 자신은 NULL을 할당한다. copy가 아니라 마치 자기가 갖고 있는걸 주는거기 때문에 소멸자에서 delete하지 않는다.
두번째는 0번 index에 MemeoryBlock(75)으로 교체할때 Move 대입 연산자가 없을 때는 생성자를 통해 임시 객체를 만들고, 만든 객체를 대입 연산자를 통해 _data가 가리키는 영역의 데이터를 copy한 후에 바로 자기 자신을 반환한다. 이 때 Move 대입 연산자와 달리 _data에 NULL을 할당해주지 않기 때문에 바로 다음에 호출되는 소멸자에서 delete가 호출되어버리고 만다.
Move 대입 연산자가 있을 때는 생성자를 통해 임시 객체를 만들고, 만든 객체를 Move 대입 연산자를 통해 0번 index에 넣어준 것이다. 따라서 일반 대입 연산자처럼 copy로 포인터가 가리키는 영역의 내용물을 memcpy_s함수로 복사할 필요 없이 포인터만 할당해주면 되고, 이때 포인터를 넘겨준(생성자에서 만들어진)객체의 멤버인 _data는 NULL을 할당해주었기 때문에 소멸자가 호출됐을때 메모리 해제가 되지 않는다.
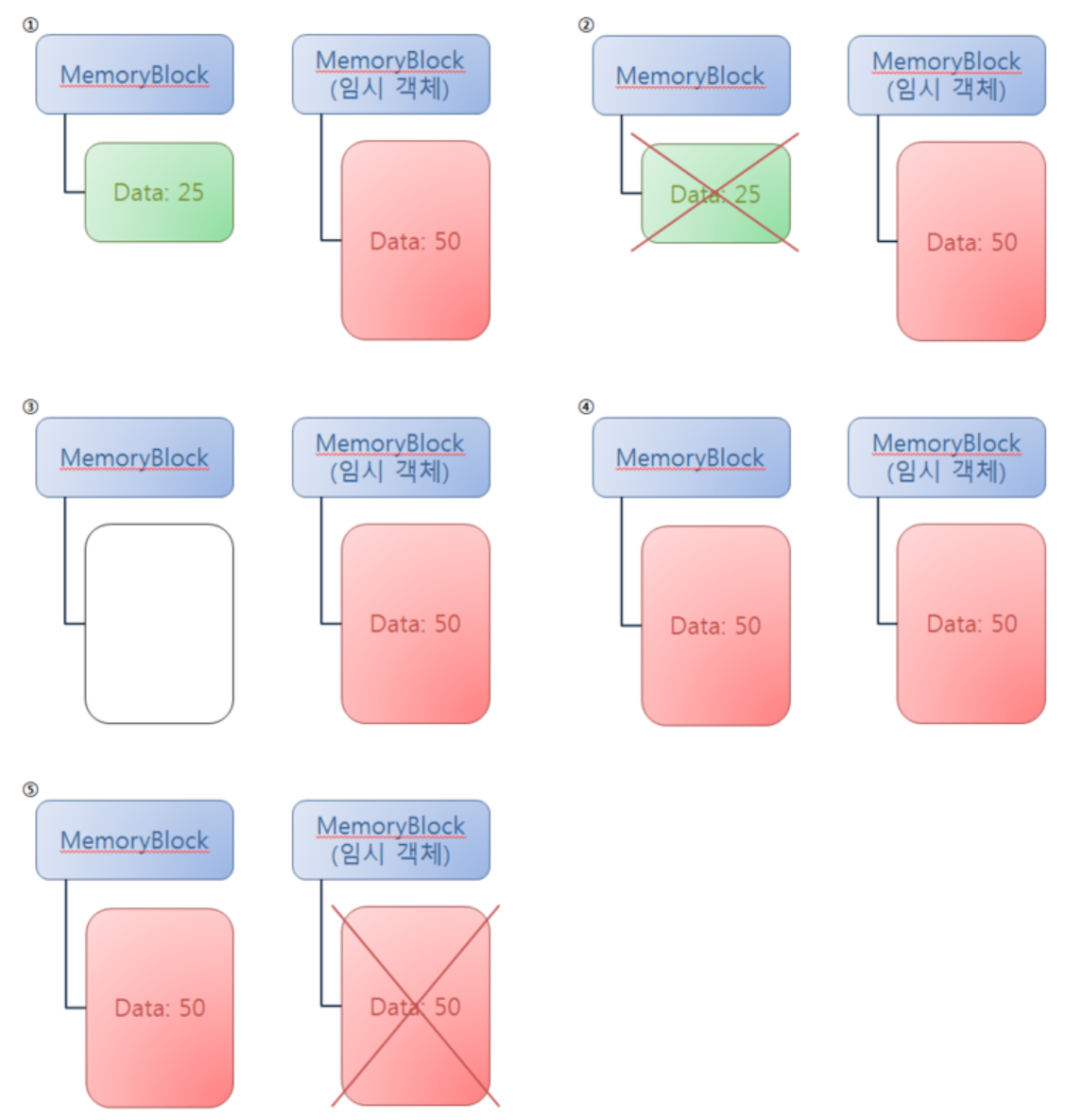
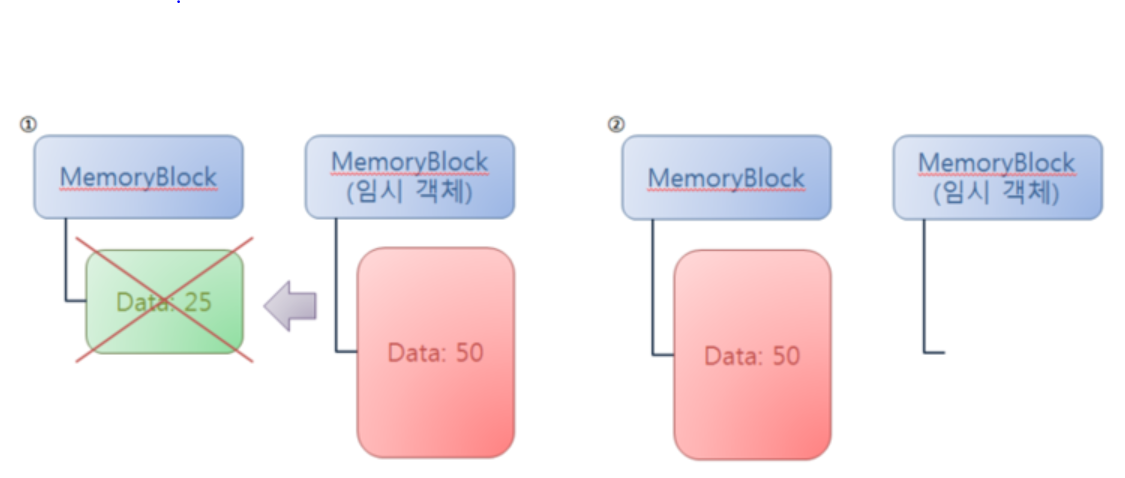
아래 사진은 0번 index에 MemoryBlock(25)가 원래 존재하고 거기에 MemoryBlock(50)을 대입하는 과정을 Move연산자가 없을때와 있을때를 비교한 그림인데 보면 이해가 더 쉽다.
(사진 출처: https://blog.naver.com/devmachine/176442133)
(1) Move연산자가 없을 때
(2) Move연산자가 있을 때
결론적으로 rvalue reference란 말 그대로 rvalue에 대한 참조를 가능하게 하는 것이다. rvalue reference가 가능해지면 move semantic이 가능해져서 불필요한 생성자 호출나 소멸자 호출로 비효율이나 낭비를 방지할 수 있다는 장점이 생긴다. move semantic이란 위의 예시처럼 어떤 리소스를 다른 대상에게 복사없이 넘겨주는 것을 의미한다.
그런데 이런 단순한 코드에서도 performace에서 차이가 날까?
아래와 같이 프로그램 시작 후 경과된 시간 차이로 performance를 비교해봤다.
int main()
{
clock_t start;
start = clock();
// MemoryBlock에 대한 vector를 생성하여 두 개의 원소를 추가
vector<MemoryBlock> v;
v.push_back(MemoryBlock(25));
v.push_back(MemoryBlock(75));
// 첫 번째 원소를 다른 MemoryBlock 으로 변경
v[0] = MemoryBlock(50);
cout << clock() - start << endl;
}*참고로 clock()의 return type은 clock_t인데 ms랑 같다고 한다.
해보니 평균적으로 3~5ms정도 Move 연산자를 사용한 것이 더 빠르다고 나온다.
이렇게 짧고 단순한 프로그램에서 조차 이정도 performance차이가 난다는 것은 복잡한 프로그램에서 더 많은 성능 차이를 보일 수도 있을 것 같다. Move연산자는 search나 sorting이 잦은 자료구조에 예시처럼 객체를 넣는 상황에서 유의미한 성능 향상을 보인다고 한다.
RValue Collapsing Rule
- 추가 예정
Reference
https://m.blog.naver.com/nortul/197598309
[C++11] Rvalue Reference #2 - Move Semantics [퍼옴]
Move Semantics Move Semantics란 객체의 리소스(동적으로 할당 된 메모리와 같은)를 또 다른 객체로 ...
blog.naver.com
https://blog.naver.com/devmachine/176442133
[C++11] Rvalue Reference #2 - Move Semantics
Move Semantics Move Semantics란 객체의 리소스(동적으로 할당 된 메모리와 같은)를 또 다른 객체로 ...
blog.naver.com
https://isocpp.org/blog/2012/11/universal-references-in-c11-scott-meyers
Universal References in C++11 -- Scott Meyers : Standard C++
isocpp.org
'공부 > C || C++' 카테고리의 다른 글
| C+ 11 스마트 포인터(unique_ptr, shared_ptr, weak_ptr) (0) | 2021.07.07 |
|---|---|
| C++ 오버로딩(overloading) vs 오버라이딩(overriding), 가상함수(virtual function) 그리고 다형성(polymorphism) (0) | 2021.07.05 |
| C 헷갈리는 char*와 char[] 그리고 string <-> char* 변환 방법 (0) | 2021.07.05 |
| 복사생성자란(copy constructor)? (0) | 2021.07.05 |
| C++11 가변 인자 함수 템플릿(variadic template) (0) | 2021.07.04 |